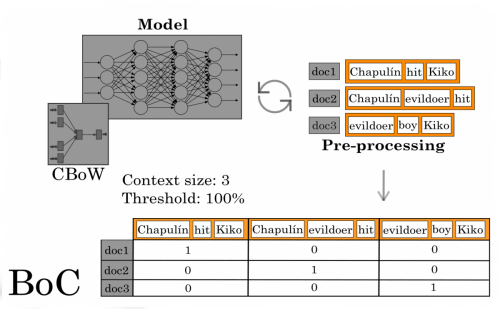
Text Mining process is essential to knowledge discovery in textual databases. In order to extract patterns from a textual collection, it is important to provide meaning to data, reflecting its characteristics by an efficient representation that transmits the original relationships of the database. Bag of words (BoW) is one of the most used text representation technique, which relates documents by the frequency of their terms based on vector space model. Among the limitations of the BoW technique is the loss of textual semantic aspects in the construction process of the matrix structure, which considers only lexical features of the text. To attenuate this problem, which impairs the reliability of extracted patterns, a new technique is proposed to semantically enrich text representations. External sources of knowledge are used to identify contexts (groups of concepts) in documents, representing them in the Vector Space Model. This new technique is being evaluated through the classification task of English databases: 20Ng (e-mail messages), BBC (news) and SemEval (reviews); and Portuguese databases: BestSports (news), Manchetômetro (news) and Buscapé (reviews), using accuracy measure.
This work was presented in a poster format at the “Encontro Paulista dos Pós Graduandos em Computação (EPPC)”, a national event held for the first time in the city of São Carlos – SP, Brazil. This is the initial synthesis of my master’s project, and for this reason the information presented in the document does not fully correspond to the final project developed.